Exporting interaction history data from the relational database
You can export interaction history data from Pega Customer Decision Hub into files in the specified repository. You can then send the exported interaction history files to downstream operational, reporting, and analytics systems and combine it with other data to provide more comprehensive reporting.
In on-premise implementations, you can do a straight database (DB) extraction or DB-to-DB transfers. However, these methods are not available for systems implemented in Pega Cloud.
The alternative method described in this article relies on data flows and a file data set. It is suitable for all deployment types, including systems that run in Pega Cloud.
Prerequisites
To export interaction history data to files in the repository, your system must be on Pega Platform 8.3.3 or later.
Interaction history structure
Pega Customer Decision Hub stores interaction history data in the relational database. The data is divided into classes that represent the Fact table and the associated dimensions. Because of this structure, exporting interaction history requires the creation of a class, in which you can combine the Fact and dimension data before exporting it to a file. For more information about the interaction history tables and classes, see Pega Customer Decision Hub Interaction History data model.
Designing the export process
To start exporting interaction history data into files in the repository, you need to create several artifacts:
- A class that you can use to combine the Fact and Dimension data. Let us call it the IH Extract class.
- The primary data flow that combines all the data for a single interaction history record in the IH Extract class, and then exports this data into a file in the repository (see example below).
- The secondary data flow that retrieves the Fact ID and Dimension record IDs for the desired record, and then feeds them into the primary data flow (see example below).
- A file data set that is used as the destination for the primary data flow. This file data set specifies a file path that points to a folder in the repository in which the exported files are saved. The file data set also defines the parameters of the exported files, such as their format (CSV or JSON), date and time settings, and the property mapping.
- Optional: If you want to run the export data flow on a regular
basis, you need to create two additional artifacts:
- A wrapping activity that calls the export data flow.
- A job scheduler that runs the wrapping activity according to the specified schedule.
Data flow examples
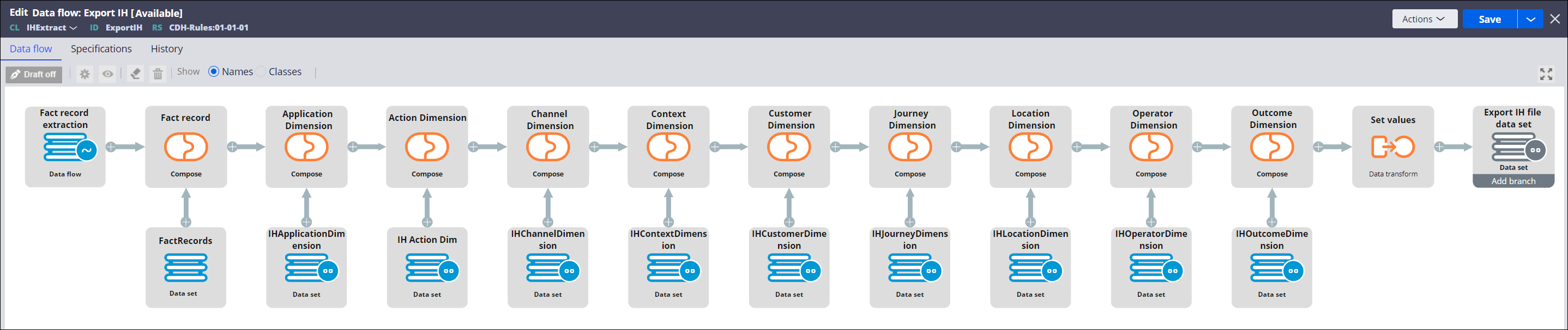
The Export IH data flow in the following figure is an example of the primary data flow that you can create to export interaction history data. For input, the primary data flow uses the secondary data flow, from which it retrieves a list of Fact ID and Dimension record IDs. Next, it combines the Fact ID and Dimension record IDs with relevant records retrieved from data sets in the Fact and Dimension classes, and adds them to the IH extract class. Finally, the data flow exports the relevant records into a file, using the file data set.
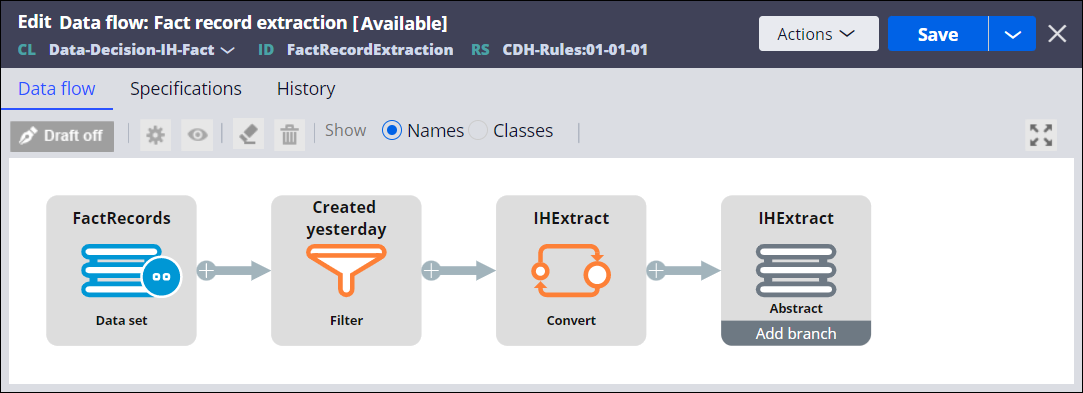
The secondary data flow (Fact record extraction in the following example) contains a filter that selects the records that were created on the previous day. The data flow uses a data set as the source, but you can also use a report definition or even an abstract source, depending on the desired outcome. The output of the data flow belongs to the IH Extract class and consists of all the Fact and Dimension IDs. The primary data flow (Export IH) uses this data to pull the relevant interaction history records.
Final considerations
- You can transfer the exported file to a downstream system using a file listener and a connect-ftp rule.
- You can add more properties to the extracted file by changing the mapping in the
file data set.
- You can add any existing interaction history properties (both Fact and Dimension) right away.
- To add new properties, you first need to add them to interaction history by following the standard process, and then you can add them to the file data set for export.
- In the Export IH data flow, you can add simple data transformations using a data transform, just before the file data set output.
- You can run the export manually for different purposes, for example, to do a
full extract, extract a specific action, or a specific campaign run. To do that,
follow these steps:
- Modify the secondary data flow, for example, by adding or removing filters.
- Change the file data set destination to prevent interfering with scheduled data transfers.
- On the primary data flow page, click .
Previous topic Exporting customer data from Pega Customer Decision Hub Next topic Recommended: Materializing interaction history summaries